My team uses Postman a lot. We store our collections in git. But we don’t want to store our secrets there. Postman is kind enough to allow users to create environments to hold those secrets.
Even with environments, the need to keep secrets secret gives us a configuration problem. Setting up a new environment involves some clicking around into Azure keyvaults and making sure we’ve given the right secret the right name. It can be tedious. And that’s if we remembered to document where each key lives. If not, it can be downright frustrating!
Not my favorite way to spend my time.
So I put together a little tool to do the hard work. The idea is to document the environment in our markdown documentation, point a tool at it, and have it create an environment suitable for pasting into Postman.
Pretty great, huh?
Well, that’s really just the intro to what I want to write about, which is the piece of code that pulls the environment table out of a markdown file. Excited yet?
It’s a story of two refactorings (and an initial assumption that turned out to be pretty good), of turning spaghetti logic into a nice tight piece of code, and trying to make the code as communicative as possible.
Act One: An initial assumption, and some spaghetti.
One of my design goals for this project was that it would be self-contained. I didn’t want to pull in external libraries to parse markdown. That was okay, because as a specialized tool, the code to extract data from markdown could be fairly dumb.
Based on past experience, I made an assumption: I would need to keep track of named states, as opposed to a basic approach of comparing to previous lines, or the status of a handful of variables and flags. It’s easy to get into trouble when you’re trying to understand state based on multiple conditions at the same time:
if len(rows) == 0 and found_label_header and is_table_row(current_line) and not finished_target_table: # Even with good variable names, what does this even mean?
Compare that to: Easy to get from there to “Therefore, we’re starting to process our starting table!”
if state == STATES.TARGET_LABEL_FOUND and is_table_row(current_line): # Oh. If we've found a header containing the label we're looking for, but not started in on the table, and the current line is a table rowEasy to get from there to “Therefore, we’re starting to process our starting table!”
(Note: it’s not how I wrote the code, so I can’t be certain, but I’m pretty sure there’s a bug in the first (non-state) example. What if we’d already been through a table so rows was non-empty? And that’s how it’s easy to get in trouble.)
So one of the very first things I did was to sketch out a state diagram.
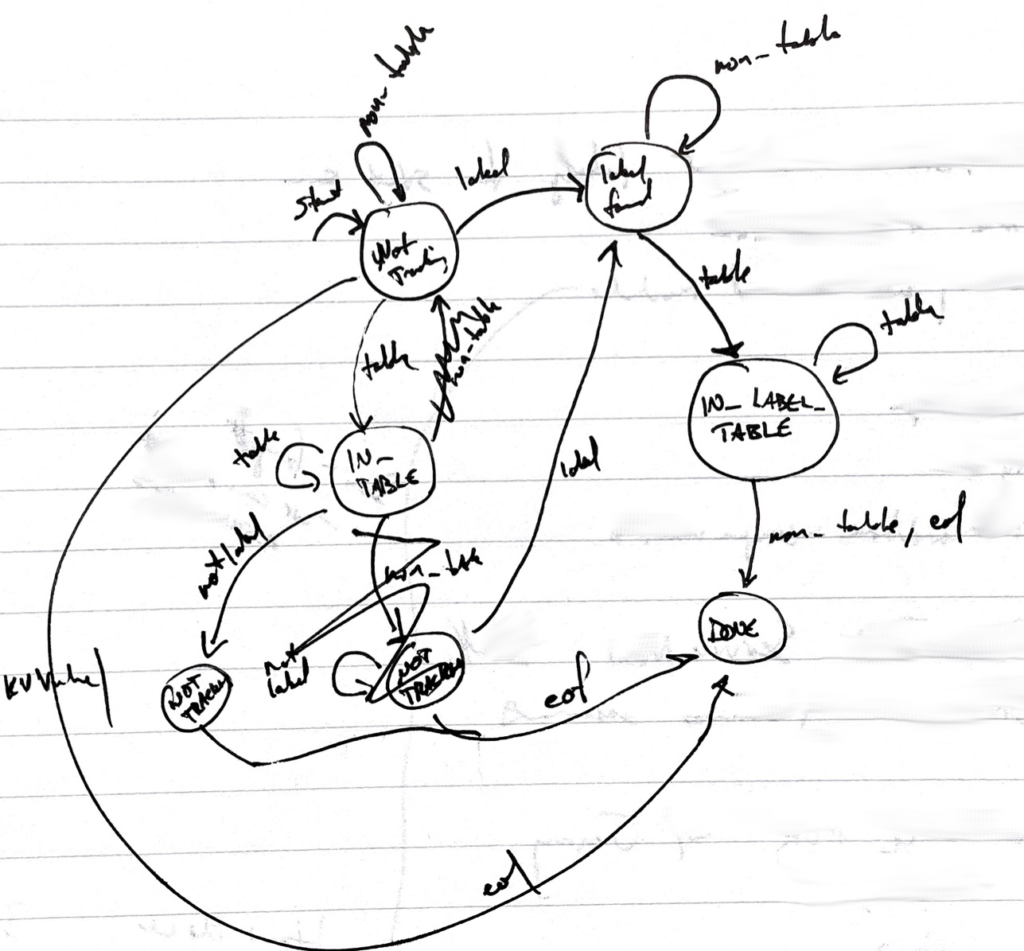
Lovely, if barely legible. The scribbled-out parts make it even lovelier. (Then again, how much time did I save by realizing I was modeling things wrong while it was still on paper, as compared to a few dozen lines of code in?)
Armed with a pretty good idea of what the states were, what caused each change in state, and an editor, I started to test-drive some code. After a while, and a little bit of refinement of the state list, the code looked a little something like this:https://github.com/mattschoutends/postman-environment-builder/commit/ea0cedb49d68947c01beb46631d57d839dd38e71 (Actually, it looked exactly like that.)
That’s pretty clean. A defined list of states, a couple of well-named helper functions (ignore the fact that is_table_line is actually wrong, which I realized embarrassingly late in the development process), and a few well-defined nested conditionals. Not bad.
Then again, looking at the “well-defined nested conditionals” was starting to feel like looking at spaghetti logic.
Act Two: A refactor!
Not only was it starting to feel a little like spaghetti, I felt like I was seeing a repetitive structure. Based on the starting state, the code checked some condition. If that condition was met, three things might happen:
- The state might change
- The
table_textlist might be cleared - The
table_textlist might have the current line appended
(If #2 happened, #3 would also happen. It happened all on one line, but keeping those in mind as separate operations could be useful.)
I asked myself if it would be possible to represent the repetitive structure as a data structure. It turned out to be pretty easy. I was already thinking about rows and columns, since I was extracting tables. I made a list of column labels, and a bunch of state transition “rows”. The rows contained:
- Current state
- Condition (a function name)
- State to transition to
- Should the program clear the table_text list?
- Should the program append the current line to the table_text list?
A little bookkeeping work turned the relatively human-readable table into a useful data structure for the program to use (a dictionary keyed by starting states, where the values are lists of transition “rows” converted to nicely-labeled dictionaries that the program can check).
What had been about 35 lines of nested conditionals turned into a half-dozen lines of code. (With one unfortunate bug that, with the set of state transitions at the time, never got triggered. Spoiler: It’s using continue instead of breakon line 7) https://github.com/mattschoutends/postman-environment-builder/commit/5a76ce7b58ae1a84d7b212c6af8823c4c65c7fa9
for transition in possible_transitions:
if (transition[TRANSITION_LABELS.CONDITION_FUNCTION](line)):
state = transition[TRANSITION_LABELS.NEXT_STATE]
if transition[TRANSITION_LABELS.SHOULD_START_NEW_TEXT]: table_text = []
if transition[TRANSITION_LABELS.SHOULD_APPEND_TEXT]: table_text.append(line)
continue
if state not in TRANSITIONS:
break
Not bad! The bookkeeping code makes it a bit longer than I’d like, but still. Not too shabby!
Well, mostly. Those bare True and False items in the table bothered me. They’re not exactly hard to follow, but they’re also not very expressive. It wasn’t bad, I thought. Not with so few state transitions.
Remember when I said is_table_line was actually wrong? Well, I’d started writing my tests with some bad test data. I’d separated my table headers from the table body with a line of dashes only (------), not dashes and pipes (| --- | --- |). As I fixed my test data and started fixing code, I needed to add a few state transitions.
And suddenly, that little bit of smell with the bare True and False got much harder to look at.
Act Three: Another Refactor!
With a few more rows, the raggedy trailing edge of the line felt like it was hiding behavior. This was especially true when it took a while to figure out a bug. There was a copy/pasted line with a False that should have been `True`, and it was really hard to spot, hiding in the middle of a line.
I wanted to change the transition “table” to be even more expressive, and to highlight the places where things really happened. It seemed like it would be useful to distinguish between lines that just marked time and lines that did something to the list.
So that’s what I did. Instead of leaving the table as a list of lists, I turned it into a list of dictionaries generated by function calls.
Which, reading it, sounds pretty unhelpful.
But when looking at the code, it’s the difference between
[STATE.IN_TABLE, is_table_dash_row, STATE.ON_TABLE_DASH_ROW, False, True],
[STATE.IN_TABLE, not_table_line, STATE.FINISHED_UNLABELED_TABLE, False, False]and
transition(STATE.IN_TABLE, is_table_dash_row, STATE.ON_TABLE_DASH_ROW, append_line=True),
transition(STATE.IN_TABLE, not_table_line, STATE.FINISHED_UNLABELED_TABLE)
Using default parameters in the function meant that all the False values could be left out.
The function also had the nice benefit of simplifying some of the bookkeeping code. Dictionary keys could be set, so the list of labels (used for keys) could go away.
Conclusion
I’m pretty happy with how this chunk of code turned out, relative to the design goals I had for it. It’s relatively small, concise, and makes the intent easy to extract.
The key refactor was Act Two, making state processing a deliberate abstraction, instead of something implicit and accidental in a mass of spaghetti. Once the state processing was separated from the state transitions, it was suddenly really easy to see (1) what the state transitions were and (2) what the program might do in each state.
Was it worth the extra time for the refactoring? Yes. The first refactoring made it much easier to add states when needed. The second would have made it much easier to find the copy/paste bug that forgot to clear the list.
Leave a Reply